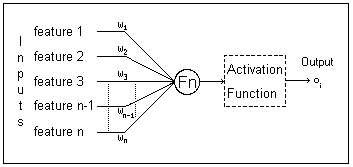
Figure 1: A simple neural network topology, with features, weights and a
single output unit.
This paper presents a description of an artificially intelligent model for predicting the outcome of particular sporting contests. It is intended as an interesting case study of using neural networks for predicting probabilistic events in a sporting scenario. The model used is a multi-layer perceptron and it is presented with a number of features representing the performance of various sporting teams. Generally more complex than much of the free stuff available, the outcomes are considerable and pleasing. The system performed quite well and successfully predicted the winner in over 70% of the matches. Results also include a study of which features are most useful, the results of "live" testing so far this year and for interest sake, the amount of money this system would have won if it was placing bets at a sports betting outlet during the season.
This paper explores the utility of neural networks, in particular
multi-layer perceptrons for predicting the outcome of sporting contests, given
only basic information. This is a less traditional application area of neural
networks and somewhat of a novelty, however the basic principals of machine
learning still apply. Additionally, attaching to predictions an indication
of how certain the predictor is, and rewarding such predictions properly, are
important issues in many fields.
The data used in this work was taken from a number of different seasons
of the National Rugby League (NRL) competition [8], with detailed
results presented for the 2002 season. For the previous three years
(1999-2001) the competition structure consisted of fourteen teams, each playing
exactly one game per week, meaning seven matches were contested each week.
A total of twenty-six weeks of competition are played in the regular season
totalling one hundred and eighty-two matches.
For the 2002 season there were fifteen teams and usually fourteen of these
play in any given week (with one team having a "bye"). This season was
used for "live" testing with one hundred and eighty-nine predictions made in
total.
The data contains noise in that there are details influencing the contest
outside of those which are being captured in the feature set. Firstly there is
what is often referred to as individual "form" of the players, however it is believed
that in most cases, the overall skill level of the team will transcend the bad
form of individuals. Secondly there is the fact that the
skill level of the team can be affected by the unavailability of "star"
players due to injury, suspension or representative duties (players getting
called away to play for their state or country). In the most extreme case,
one team was left without eleven of their thirteen regular players due to representative
duties and this is not reflected in the feature set used (see
Section 3.1 for more information about the
features).
There was a conscious effort made to ensure that there was no subjectivity in
the feature set. For example, it would be desirable to include some measure
of "star-availability" in the feature set, but it is almost impossible to
accurately quantify the value of an individual player to their team.
The paper is organised as follows: Section 2 gives a
background on the neural network engine used to make the predictions;
Section 3 describes the raw data used and the feature
extraction process; Section 4 details the
experiments conducted and the results of work, including comparisons to
"expert" tippers and the potential success at sports betting
outlets; a breakdown of the utility of different features is presented in
Section 5; future work is presented in
Section 6 and Section 7 contains
the concluding remarks.
Introduction
Modelling the Feature Space
One of the key features and the main reason for using neural networks (NNs) to model the feature space is the ability of NNs to learn the relationship between inputs and outputs upon presentation of examples [2]. It is only necessary to provide a set of sample data (also known as training data or training set) to the network and the use of learning (or training) algorithms such as back-propagation perform an adjustment of the network to better model the problem domain.
There are many types of neural networks and one of the most popular models is the multi-layer perceptron (MLP). MLPs associate a weight with each of the input features (see Section 3.1 for a discussion of the features in this domain) according to that features importance in the model (see Figure 1). This type of network topology is imminently suited to the well-defined domain discussed in this paper because several features exist and a weighting must be associated with each according to its contribution to the solution. These weights can be set to specific initial values (possibly to facilitate an intentional bias) or simply randomly assigned. The learning algorithm then adjusts the weights to minimize the error between the target output (the desired output provided in the learning examples) and the observed output (the output as calculated by the MLP).
Figure 1: A simple neural network topology, with features, weights and a
single output unit.
There are a number of learning algorithms which can be used to optimize the weights in MLPs, such as back-propagation, conjugate gradient descent and Levenberg-Marquardt [2]. The two learning algorithms concentrated on in this work were back-propagation and the conjugate-gradient method, both classical algorithms which are effective, relatively simple and well understood. Some argue that other learning algorithms often perform faster [3], but as this study deals with only a very small number of features with no requirement for real-time operation, the above-mentioned advantages outweigh any perceived increase in speed.
Back-propagation and the conjugate-gradient method work by iteratively training the network using the presented training data. On each iteration (or epoch), the entire training set is presented to the network, one case at a time. In order to update the weights a cost function is determined in terms of the weights and its derivative (or gradient) with respect to each weight is estimated [10]. Weights are updated following the direction of steepest descent of the cost function. A common cost function and the one used in this work is the root mean squared (or RMS) error. During experimentation with the two methods back-propagation was a little slower to learn that the conjugate-gradient approach, but both methods resulted in almost identical error rates. Back-propagation was slightly more accurate, making one more correct prediction than did conjugate-gradient. Further discussions of MLPs and the two learning algorithms can be found in most neural network texts, for example [11] and [2].
The raw data for this work was originally provided by TAB Limited in the form of a series of spreadsheets (one per season). These spreadsheets contained the names of the teams competing in each game, the final score for each team and the dollar amount paid by TAB Limited for successfully picking the winner of the game. There are twenty-six weeks of competition in each of the seasons. From this raw data it is possible to determine weekly statistics (features) for each team including their current success rate, their recent performance, the points they've scored in the competition to date (to rate their offensive capabilities) and the points scored against them (to rate their defensive capabilities) and several other indicative features.
A number of features were extracted from the raw data for use in the automatic tipping process. A conscious effort was made to ensure that no subjective features were included in the feature set. For example, the inclusion of a "star-availability" measure would be desirable, as obviously the unavailability of leading players due to suspension, injury or representative duties can greatly effect the performance of the team as a whole. The problem with this however is that first, it requires human intervention to monitor the domain and determine availability, which goes against the concept of an "automatic" tipper, and also it requires some subjectivity on the part of the overseer. For example, it is impossible to predict with any certainty that player A is more valuable to team X than player B is to team Y, and different individuals will subjectively select different values for this feature.
Features obtained were based solely on details such as scoreline, recent performance and position on the "league ladder" relative to other teams. This removes the need for any human involvement in generation of features and removes any bias or subjectivity on the part of that human. A set of features was obtained for each team, for each week of competition, and are as follows:
If a team did not play in a given week (this is relevant only to the 2002 season) the feature values from the previous week were brought forward to the current week. Additionally, when required, the feature values were averaged over the number of matches played. This was done so that a meaningful comparison may still be made between two teams which have played a different number of previous matches.
The experiments conducted involved firstly extracting the features described in Section 3.1. The next phase was to construct the model. As mentioned in Section 2 the choice was made to use a multi-layer perceptron (MLP) to model the features and back-propagation (which proved slightly more effective than the conjugate-gradient method) to facilitate learning. Specifically, a three-layer MLP was used with nineteen input units (one for each feature), ten hidden units and a single output unit. The output unit is normalised to be a value between zero and one inclusive.
The feature set values were calculated for each team for each week of competition. The MLP was trained using all examples from previous weeks (except for the first week obviously, as there was no previous week). Predictions were made for the current week by using the MLP to calculate an output value for each team based on that teams feature set. An output value of close to one for a particular team indicated a high level of confidence that the team was going to win their upcoming match, and an output value of close to zero indicated a low confidence level.
The output values for each team competing in each game were calculated and the team which had the highest output value (that is, the highest confidence that the team would be victorious) was taken as the predicted winner (or tip) for that match. Success rates calculated include the hit rate, or the proportion of tips for which the predicted winner of a game matched the actual winner.
The results are split into two separate parts: the first part shows the performance of the system tested (as described above) on a database of results from the three previous seasons; the second part involves an examination of the system performance in the "live" testing scenario conducted during the 2002 season (details of which are given below).
It is difficult to measure the success of the system as there are few benchmarks for use of neural networks in this domain. Systems with a similar structure have been used to perform other predictive tasks, such as use of neural networks to predict prices on the stock market [4, 14, 9, 7, 6]. These systems do not typically perform with outstanding success and are rarely more effective than a naive human investor (largely due to the fact that stock market prices are effected by a very large number of variables, many of which are not quantifiable).
A small number of systems exist which attempt to apply neural networks to the sporting arena with varying levels of success. Australian Rules football has been the subject of the most significant effort in computerised sports prediction by a number of groups [12]. The most thorough study into applying neural networks to sports prediction is described in [1] and reports a best-case results of 58% using data from the 1999 National Rugby League season.
Regular (human) winners of tipping competitions (where each participant attempts to pick a winner for every game on a week-by-week basis) typically have success rates of somewhere between 65% to 70%. Given that fact and the success rates of other computerised sports prediction systems, the optimistic aim of the approach described in this paper was a result of over 70% success.
Testing on data from previous seasons yielded quite promising results. The approach was tested on the 1999 season (for the purpose of comparison with other reported results) and exceeded expectations resulting in a success rate of 76.2%. The testing on the 2000 season resulted in exceptional performance at just under 83.0% success rate (although it should be noted that the 2000 season was particular "well behaved" in that the home team won on the vast majority of occasions). The 2001 season resulted in an overall success rate of 71.4%, with results obtained from other human-based competitions suggesting this was a more "difficult" season to predict. The results for the 2002 seasons are discussed below.
In 2002, the automatic tipper has undergone a public "live" testing under the name of "McCabe's Artificially Intelligent Tipper" or MAIT, which has received some interest from the media. The live testing environment involves predictions for each week being made at the end of the previous week of competition (that is, several days in advance). These predictions are posted on an internet site [5] and printed in the Townsville Bulletin, a local newspaper. A summary of the results for 2002 appears in Table 1.

Table 1: The various performance characteristics for the tipping system using data from the 2002 National Rugby League season.
It has already been shown that the automatic tipper successfully modelled elements of sporting contests, at least to the point where it was able to outperform most human tippers. It did this by finding a balance of weights to associate with the different features, some clearly less important than others.
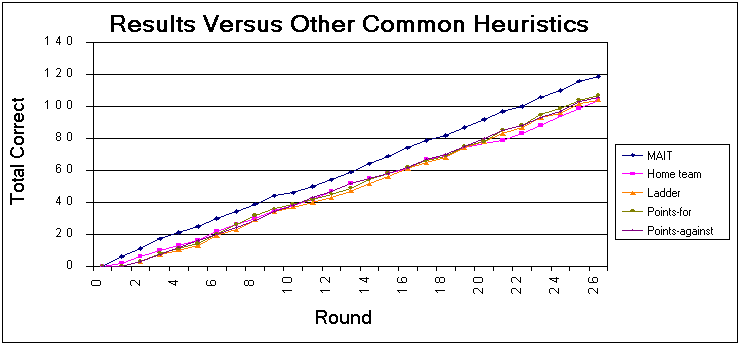
In further experimentation, the importance of each of the individual features was considered. Figure 2 is a graphical presentation of the performance of the top performing features for season 2002 and includes the results for the MAIT system. As can be seen, MAIT clearly outperformed all of the simple heuristics.
There are a number of directions of possible future work in this area. The natural progression with future work is to assess the effectiveness of the automatic tipper on different seasons in the National Rugby League competition, as well as different leagues (such as the English Rugby League) and indeed different sports. One of the difficulties in training the system on different leagues, seasons and sports is the lack of availability of detailed training data. Without the assistance of other organisations it is often difficult to obtain records from previous seasons.
From a financial point-of-view it would be advantageous to examine more advanced betting strategies to maximize return and minimize the number of bets lost. Additionally the development of a richer feature set to better capture the environment of the sporting contest, such as to account for player availability, performance in different weather conditions etc., should be included.
Despite an existing "novelty" value of this work, there is still theoretical interest in the modelling of features in a noisy environment and the use of machine learning techniques to predict probabilistic events. One of the attractions of sport in general is that there are so many factors which can affect the outcome and that on any given day, either side can win a sporting contest. This same fact is what makes the prediction process so difficult and why so much time and money is spent by individuals trying to predict winners in various "tipping competitions" and gambling outlets.
This paper described an attempt to generalize and model the behaviour of teams in sporting contests, using the National Rugby League competition as a specific example. Results were reported for various seasons which compared favourably against other human "expert" rugby league tippers.
Results could have been further improved, taking into account details such as player availability (unavailability of "star" players due to representative duties, injury or suspension are not considered by the neural network). The multi-layer perceptron used managed to adapt very quickly and perform well despite the limited information and the outside influences not included in the feature set.